How do I integrate Amazon S3 bucket with Brand Control Center to push the analytics data?
Integrating your S3 storage with the Brand Control Center enables automated delivery of analytics data directly into your data infrastructure. This allows you to:
- Export analytics for external BI tools and dashboards
- Maintain centralized data storage for reporting and compliance
- Enable advanced data analysis and modeling
- Automate data pipelines without manual exports
- Align analytics with your internal data ecosystem
This integration ensures your data is always accessible, structured, and ready for deeper insights.
Guide: Step-by-step setup
Step 1: Open S3 Storage configuration
- Log in to your Brand Control Center
- Navigate to Settings
- Select Data Source > S3 Storage
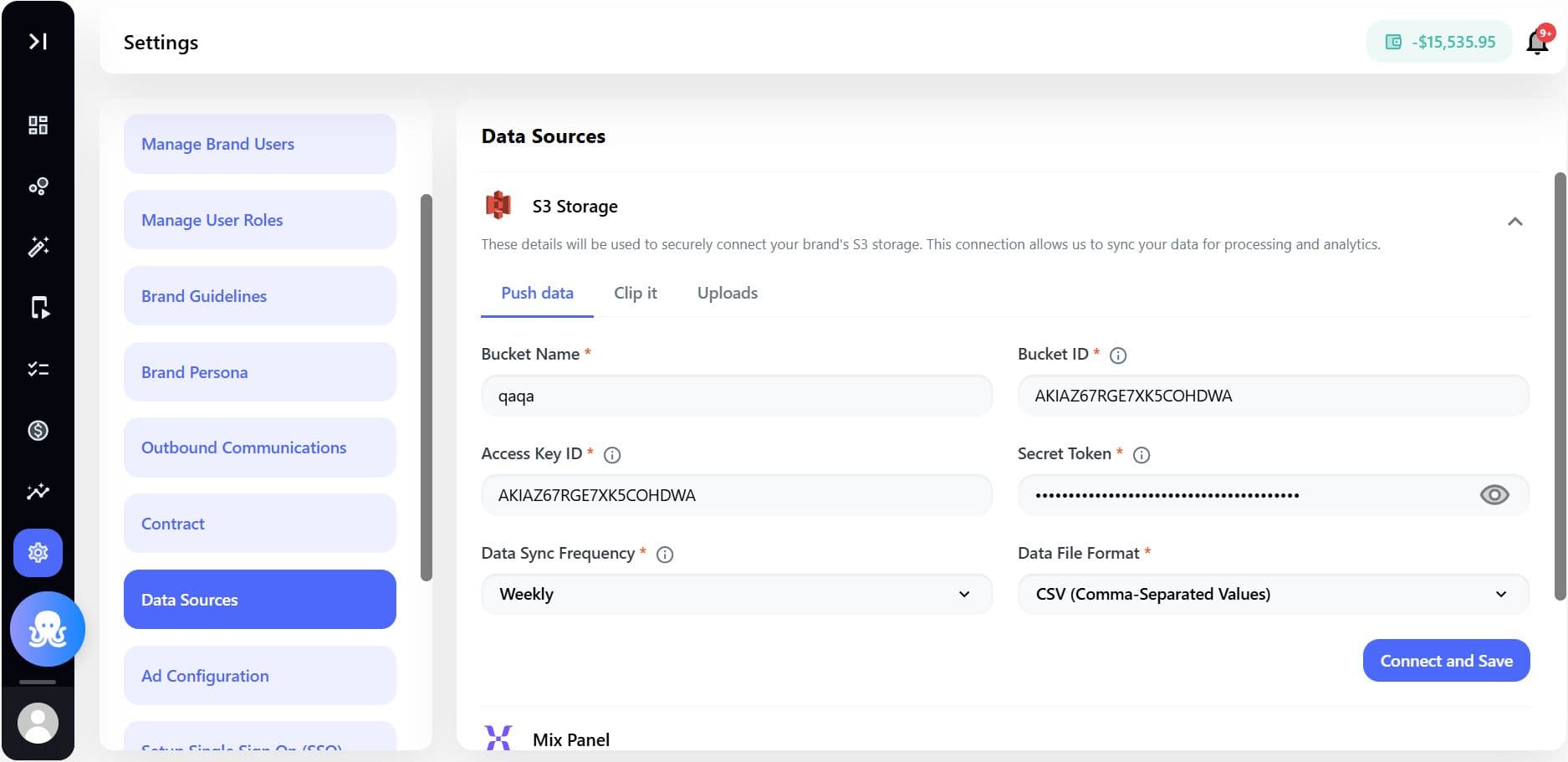
Step 2: Enable “Push Data”
- Locate the Push Data configuration section
- Enable the option to start configuring your S3 integration
Step 3: Enter S3 bucket details
Provide the following required details:
- Bucket Name - Your S3 bucket name
- Bucket ID - Unique identifier for the bucket
- Access Key ID - AWS access key for authentication
- Secret Token - AWS secret access key
Ensure the credentials have proper permissions to write data into the bucket.
Step 4: Configure data sync settings
Define how and when data should be pushed:
- Data Sync Frequency
- Daily
- Weekly
- Monthly
- Data File Format
- CSV
- Parquet
Choose formats based on your analytics and processing requirements (Parquet is recommended for large-scale analytics).
Step 5: Configure ClipIt & Uploads data paths
For content ingestion workflows, provide additional details:
- Region - AWS region where your bucket is hosted
- Path - Folder path within the bucket for storing data
This ensures data from:
- ClipIt workflows
- Uploads workflows
is correctly structured and organized within your S3 storage.
Step 6: Save and validate configuration
- Click Save / Apply Settings
- System will validate the connection and credentials
- Once successful, data push will begin based on configured frequency
How it works (System behavior)
- BCC generates analytics data based on platform activity
- Data is packaged in the selected format (CSV/Parquet)
- Files are pushed to your configured S3 bucket at defined intervals
- Separate paths ensure structured storage for different workflows (ClipIt, Uploads, etc.)
Best practices
- Use Parquet format for better performance and storage efficiency
- Organize S3 paths by date or category for easier querying
- Restrict access keys with minimal required permissions
- Monitor sync jobs to ensure data consistency
- Integrate with tools like data warehouses or BI platforms for advanced reporting
Specs & Limitations
- Requires valid AWS credentials with write access to the S3 bucket
- Sync frequency defines when data becomes available externally
- Incorrect region or path configuration may lead to failed uploads
- Data schema depends on analytics configuration within BCC
- Large datasets may take time to sync based on volume
Related articles
- How can brands request and manage camera, microphone, and gallery permissions?
- How Do User Authentication Mechanisms Work in the Genuin SDK?
- How Can Brands Use an SDK to Build Communities and Video Experiences Inside Their Mobile Apps?
- How does the Genuin SDK render ads and deliver the consumer experience?
- How Do Push Notifications Work with the Genuin SDK?
- How Does Zero-Party Data from the Genuin SDK Power Brand Communities and Media Revenue?
